Faisal Ahmed Pasha Mohammed
Data Access Object (DAO) Design Pattern in Java EE
Discussing the implementation of the Data Access Object (DAO) Java EE Design Pattern.
Table of Contents
Introduction
Ever since I came across the DAO design pattern, I am in love with it. Because, it makes my application design process easier. I still remember the early days of my web application development where I started developing a web app for my team to make daily project reporting easier. The project started out of my personal interest. Initially, I started using the Oracle database. After some days, I began using MySQL on my laptop because it was better working on it when compared with Oracle DB. As soon as I decided to switch to MySQL from Oracle DB, I started facing the awful task of changing many parts of my already developed code. It was a frustrating experience. During such period I came across the DAO design pattern and it solved my data access layer issues forever. It remains my favorite to this day. I have been solely developing web applications and DAO is the part of my application that gets developed first, immediately after designing my data model.
DAO design pattern is part of the core J2EE design patterns. The pattern lets you separate the application’s data access layer from other parts of the application. Usually, web applications are developed following the Model View Controller (MVC) 2 design pattern, where MVC are three different parts of the same web application. The components of these three parts interact with the application’s database for CRUD (Create Read Update Delete) operations. Without having a separate layer for database interactions, we find ourselves using the same JDBC API methods from various components. This results in boilerplate code apart from the tight coupling. Numerous classes that belong to the Model part of our MVC 2 based application would require change if we make changes to our persistent storage. Imagine the scenario of moving from a RDBMS to a file based (XML or plain files for example) system for persistent storage! Without a separate data base access layer, we would definitely end up modifying a big chunk of our existing codebase apart from writing whole lot new!
Having a separate and uniform layer for data base access brings us benefits like:
- a single layer for all components of the application to interact with database irrespective of the type of the database
- decoupling the boilerplate database access calls from the other parts of application
- easy to maintain and increases portability
In this little project, I will demonstrate a fully functional DAO implementation using a simple database.
Example Implementation
In our example implementation, we first begin with designing our data model. To keep it simple, I will use a database to store names/titles of books. Our database will have a single table called ‘Books’:
| Book_ID | Title |
|---|---|
| 1 | Java |
| 2 | The Java Programming Language |
That’s it. Very simple. The books database will be used by both command line and web based applications. So, it should support uniform access. We also want to see the beauty of this ‘uniform access layer’ while using two different databases - MySQL and Apache Derby. So, those are our two goals for this short project.
The DAO pattern suggests to use an object called ‘Data Access Object’ which acts as an interface for all our data access needs. This object provides the abstraction and further encapsulates the entire access to the data storage. For our object oriented application, a data access object is another object to interact with - which makes our life a lot easier.
Let’s first see, how we would have to interact with our books database without a DAO.
Here’s a simple SQL script to create the books database in MySQL 8.0. The script also inserts few books.
CREATE DATABASE booklib;
CREATE TABLE books (
book_id UNSIGNED AUTO_INCREMENT PRIMARY KEY,
title varchar(32) NOT NULL
);
INSERT INTO books(title) VALUES ('Java'), ('The Java Programming Language');
We represent a Book in our Java application as:
public class Book {
private Integer bookID;
private String title;
public Book() {
}
public void setBookID(int id) {
this.bookID = id;
}
public Integer getBookID() {
return this.bookID;
}
public void setTitle(String name) {
this.title = name;
}
public String getTitle() {
return this.title;
}
@Override
public String toString() {
return this.bookID+", "+this.title;
}
}
The below code interacts with the database:
import java.sql.*;
public class BooksDBTest {
public static void main(String[] args) {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/booklib?user=root&password=root");
Statement stmt = conn.createStatement();
String query = "SELECT book_id, title FROM books";
ResultSet rs = stmt.executeQuery(query);
while(rs.next()){
System.out.println("Book ID: " + rs.getInt("book_id") + " Title: " + rs.getString("title"));
}
rs.close();
stmt.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Output:

Now, let’s imagine the underlying database has changed from MySQL to Derby and then later to a file. We should then have to rewrite the whole code. In the above code, we are setting up the low level mechanisms (URL, credentials etc.) to ineract with the database. We can hide this. Database implementor should be able to configure the database without affecting the code.
Following the DAO pattern, we shall first design a data access object that abstracts and encapsulates our persistent storage. Below code shows how we are going to interact with the database through a DAO:
public class DAO {
public void insertBook(Book b);
public Book findBook(int bookID);
public void updateBook(Book b);
public void deleteBook(int bookID);
}
//Database client program
public class BookDBTest {
public static void main(String[] args) {
DAO booksDAO = new DAO();
Book b = booksDAO.findBook(1);
b = new Book();
booksDAO.insertBook(b);
}
}
There’s no low level mechanism that we have to care about. It’s purely object-oriented. We treat the persistence storage as an object and we interact with the object. We don’t even know what the underlying database actually is! DAO has encapsulated the data access mechanisms and also abstracted the way we interact with the database. The client code is clean.
Straight from the Core J2EE design patterns, here’s how the DAO design pattern works:
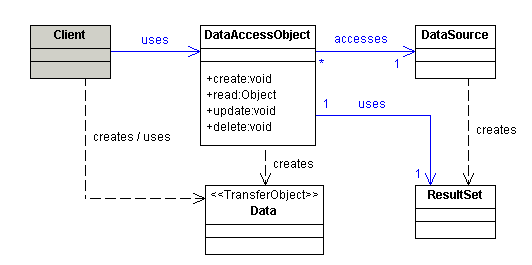
In our example, Book is the transaction object (TO) and client is the BookDBTest program. The DAO class hides how it interacts with the underlying DataSource and how it builds up the ResultSet. The client code BookDBTest cares about result - like objects interacting (message passing) with each other in an object-oriented application.
The sequence diagram from the Core J2EE design patterns further shows what we have discussed so far:
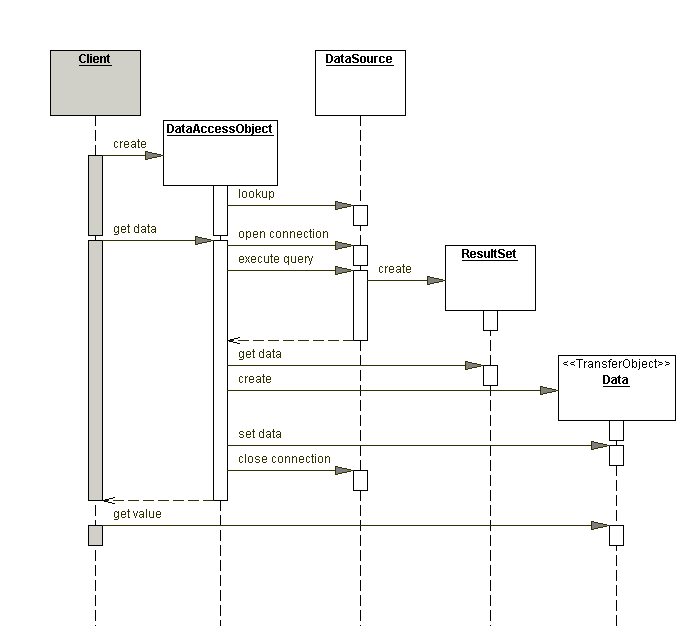
Because we are trying to use two databases - MySQL and Apache Derby, we shall implement abstract factory design pattern. If we are using only one database instead, factory pattern can replace the abstract factory pattern. Our purpose is to use a factory object to create the required DAO and give it to us. Because we want futher abstraction while creating/obtaining the DAO object. We don’t want to specify the exact class of the DAO object that we want. It could be MySQLDAO or DerbyDAO. We don’t want to get into those details. All we care about is the DAO object on which we can call the methods like DAO.getBook(int id) etc.
Here’s the class diagram for the application that we are developing:
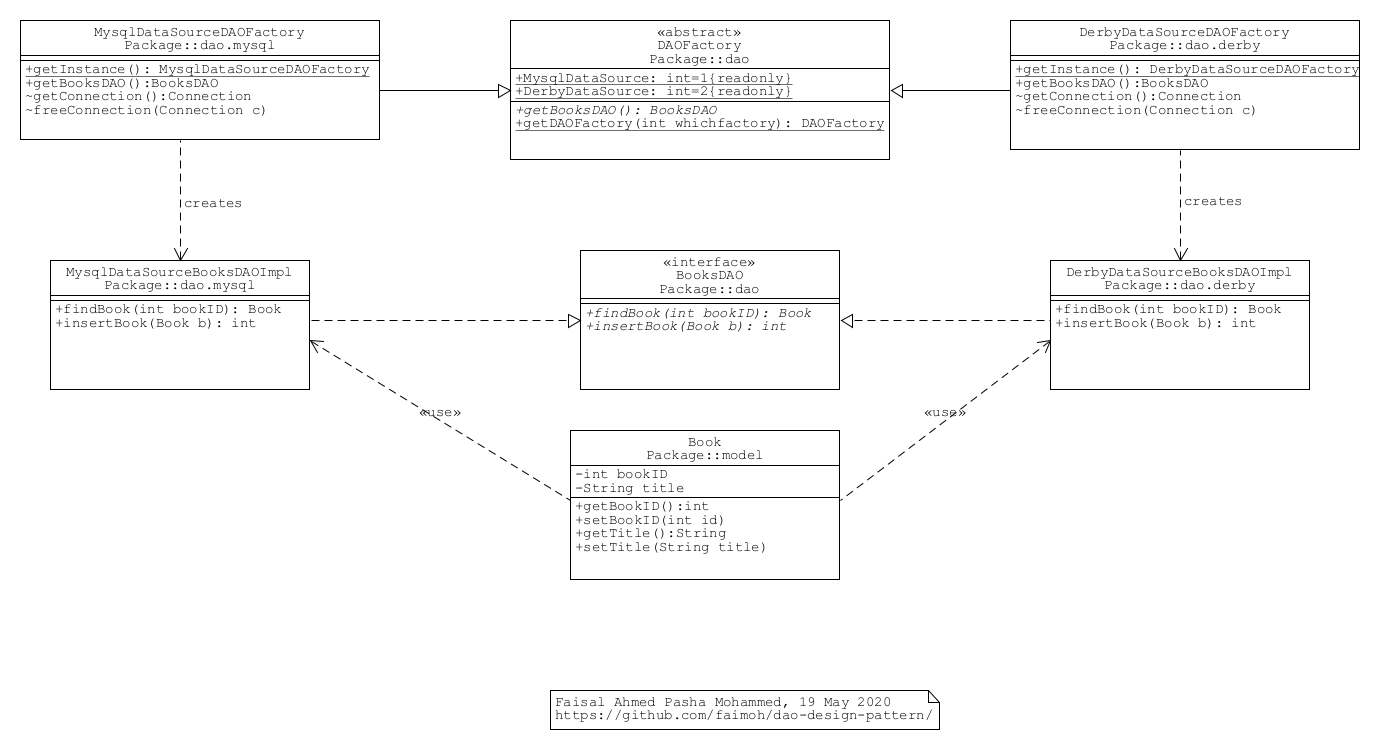
The UML class diagram is self-explaining. I’ve designed:
- a
DAOFactoryclass implementing the abstract factory design pattern - a
BooksDAOinterface for the real DAO object that we’ve discussed so far. We define the behaviour of the books database DAO through this interface. We declare all the CRUD operations here in the interface for the purpose of an uniform way to interact with any type of the actual database. This enforces all the specific database classes to implement the behaviour declared in this interface. - a
MysqlDataSourceBooksDAOImplclass implementing theBooksDAOinterface using the MySQL DataSource mechanism. - a
DerbyDataSourceBooksDAOImplclass implementing theBooksDAOinterface using the Derby DataSource mechanism. - a
Bookclass representing the Book entity. The database tablebooksrepresents a collection of such books. So, theBooksDAOobject uses theBookobject during the CRUD operations.
Based on the above class diagram, one can easily develop the Java code. However, you can find my code hosted on GitHub.
It’s important to understand that the individual DAO implementations take care of interacting with database. For example, MysqlDataSourceBooksDAOImpl takes care of interacting with a MySQL database, while DerbyDataSourceBooksDAOImpl takes care of interacting with a Derby database. These low level mechanisms are now encapsulated by the DAO object. Database client will now be not bothered about the details like driver management, connection pooling etc. All these requirements are handled by the respective DAO implementations. For the database client, the interface to interact with the database - the API - remains same - irrespective of the actual database being used.
Here’s an exmaple client program DAOTest interacting with the above discussed DAO implementation:
public class DAOTest {
public static void main(String[] args) {
DAOFactory dao = DAOFactory.getDAOFactory(DAOFactory.MySQLDataSource);
BooksDAO booksDAO = dao.getBooksDAO();
Book book = booksDAO.findBook(1);
System.out.println(book);
dao = DAOFactory.getDAOFactory(DAOFactory.DerbyDataSource);
booksDAO = dao.getBooksDAO();
book = booksDAO.findBook(1);
System.out.println(book);
for (Book b : booksDAO.getAllBooks()) {
System.out.println(b);
}
dao = DAOFactory.getDAOFactory(DAOFactory.MySQLDataSource);
booksDAO = dao.getBooksDAO();
for (Book b : booksDAO.getAllBooks()) {
System.out.println(b);
}
}
}
Output:
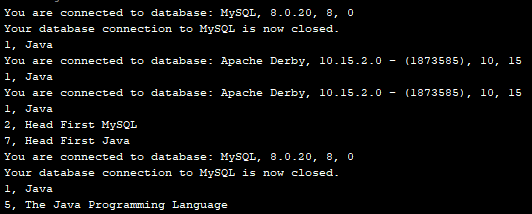
Notice that, I didn’t create any DAO object for each database - MySQL and Derby. I have just interacted with the DAOFactory object and then the actual DAO implementation object returned by the factory. There were no database specific calls were made. There was no driver management, connection establishment and termination etc. The DAO object has hidden all such complexities.
Conclusion
DAO pattern essentially has helped me in easily migrating from one database to another. Further, it has removed the complex code that is written from all the business objects (Model) of a web application resulting in loosely coupled code. It has added an extra layer that hides the persistent storage mechanisms from database client code bringing in a centralized control.
Source code of the project is available on GitHub